
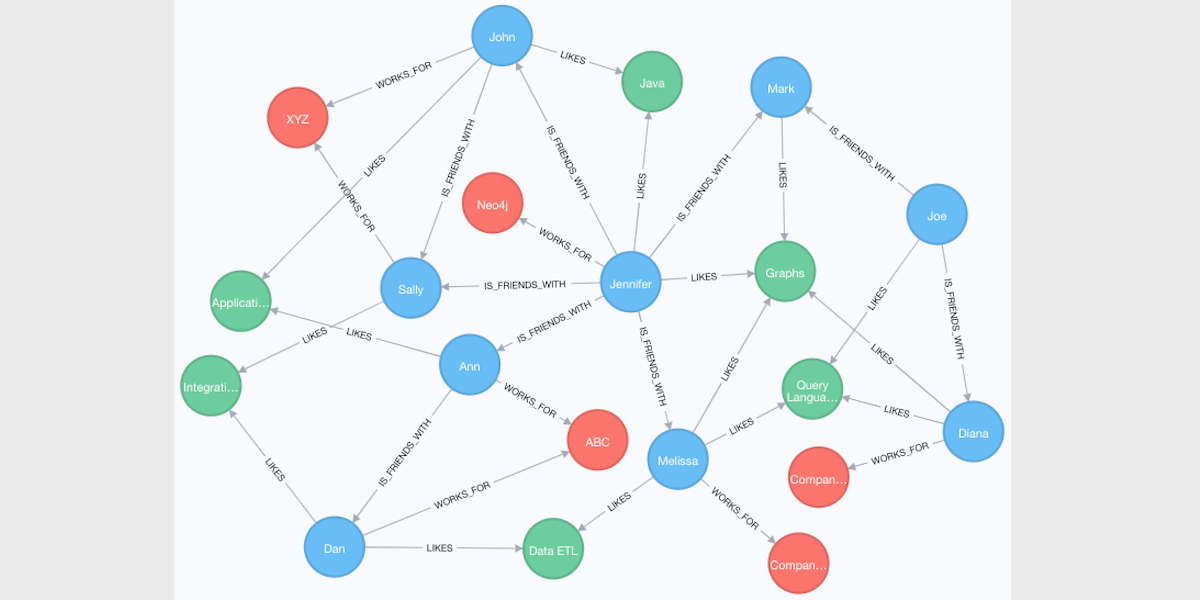
What is a graph database?
The problem: The app must store a collection of people and who they know. Sometimes it must find out everyone who knows someone who knows Bob. Sometimes it must look further for everyone who is three hops away. Sometimes it must find the friends of the friends of Bob who like fishing or listening to symphonies.
The graph database was originally designed to store networks — that is, the connections between several elements such as people, places they might visit, or the things they might use. Relational databases can find single connections between them, but they get bogged down when asked to negotiate and analyze complex relationships between multiple parties.
This can be so computationally challenging that it can threaten a business that grows too quickly. Doubling the number of users will quadruple the possible relationships, for instance. One of the early social networks, Friendster, struggled to manage the growing complexity of its social graph when it grew popular. Ultimately it lost its first-mover advantage to those with better database technology.
The graph database grew in popularity with the rise of social networks, but there’s no reason to limit it to tracking people and their friendships. It can be used to find all of the books that cite a book that was in Isaac Newton’s personal library. Or all of the chemicals that react with table salt. Or every building that can be reached by waiting at no more than two traffic lights.
The word “graph” is often confusing because mathematicians use the word for several different constructs, and most people have experience with only the best known version: the line that plots the relationship between two variables like time and money. By contrast, graph databases specialize in storing more arbitrary relationships that may not be continuous.
The graph database shines when asked to search through the networks defined by these connections. They have specialized algorithms for compiling the layers of relationships that radiate out from one entry.
Some of the common use cases
- Recommendation engines — People often search for similar products as others do. That is, if one person buys shoelaces after buying sneakers, there’s a good chance others will do the same. Recommendation engines look for people who are connected by their purchases and then look for other closely connected products in the graph.
- Fraud detection — Good customers rarely commit fraud, and fraudsters often follow the same pattern again and again. Building out a graph of transactions can identify fraud by flagging suspicious patterns that often have no connection to legitimate transactions.
- Knowledge networks — Some artificial intelligence researchers have been creating graphs of facts and the connections between them so that computers can approximate human reasoning by following paths.
- Routing — Finding a path in the world is much like finding a path in an abstract graph that’s modeling the roads. If the intersections are nodes, and the streets between them the links or edges, then the graph is a good abstract representation of the world. Choosing a path for an autonomous car just requires a sequence of nodes and links between them.
In general, standard databases can easily find connections that are only one hop away. Graph databases are optimized to handle queries that can follow multiple hops and collect all nodes within a radius. It can’t search through multiple links or hops without multiple queries.
How the legacy players are approaching it
Microsoft added special node and edge tables to SQL Server to make it simpler to execute more complicated searches. These tables can be searched with traditional SELECT commands, but they shine when the special MATCH command can look for particular patterns of items and the connections between them. A MATCH written by a dog breeder, for instance, might look for two potential parents that aren’t close cousins.
Oracle offers a separate Graph Server that integrates with its main products, and the combination will store data in both graph and traditional tables. The tool can run more than 60 different graph algorithms, like finding the shortest connection between people or looking for particularly tight groups.
Both extensions can work with standard SQL, but both are also integrating GraphQL engines for users who might want to use that query language. GraphQL, incidentally, was designed to simplify some queries. While it does a good job with graph databases, it also shines with basic relational tables.
Many users are deploying GraphQL for tasks that aren’t strictly graph applications. For example, IBM integrated the Apache TinkerPop analytics framework with Db2. Queries are written in a language called Gremlin that is translated into more standard SQL requests.
The upstarts
A number of new startups are building graph databases from scratch. Some are purely commercial, and many offer hybrid models.
Neo4j is a full-featured, open source database that can be run locally or purchased as service from Neo4J’s own Aura cloud. The company also offers tools for browsing through the networks (Bloom) and implementing more sophisticated network search algorithms for analyzing the most important nodes in the network and predicting performance. The centrality algorithms, for instance, find the most influential nodes using the number and structure of the connections. The community detection algorithms search for tightly connected groups of nodes.
ArangoDB‘s eponymous product is available as either a community license, an enterprise product, or an instance that can be started in any of the major clouds. The company says its product is “multi-modal,” which means that the nodes can either act like NoSQL key/value stores, parts of a graph, or both. The Enterprise version adds extra features for spreading larger graphs across multiple machines for faster performance. The tool works to keep connected records or nodes on the same machine to speed algorithms that require local searching or traversing.
Amazon’s Neptune is a distributed graph database that’s optimized for very large datasets and fast response times. It works with two popular query languages (TinkerPop and SparQL). It is fully managed and priced as a service that’s integrated with the other AWS services.
Dgraph is a distributed graph database with a core that’s available under the Apache license wrapped by a collection of enterprise routines that support larger data sets. The main query language is GraphQL, developed by Facebook for more general data retrieval. Dgraph has also extended the core language with a set of routines focused on searching and extracting the graph’s connections. This extension, called DQL, can execute more sophisticated tasks like finding the node with the greatest number of incoming edges matching a particular predicate.
JanusGraph is a project of the Linux Foundation that is designed to store and analyze very large graphs. The work is supported by a number of companies, including Target. The source code is released under the Apache license, and it works alongside some of the big NoSQL databases like Apache HBase, Google’s Bigtable, or Oracle’s Berkeley DB. The code is tightly integrated with many of the other Apache projects, like Spark for distributed analysis of the graph, Lucene for storing and searching raw text, and TinkerPop for querying and visualizing the results.
TigerGraph is built for large enterprises with big datasets that may want to run the tool locally or subscribe to a service in TigerGraph Cloud. The analytics are aimed at industries with well-understood use cases like the regulations that ask banks to track money flows among accounts to stop money laundering.
Is there anything a graph database as a service can’t do?
Graph databases are largely supersets of regular databases, and many of them were created by adding new table structures to existing databases. They usually can do everything a regular database can accomplish and also search through networks defined in the data, too.
Some simpler graph search algorithms may not need the extra features of a graph database. A skilled programmer can duplicate them with a bit of code. The results, though, can be much slower, especially when the analysis requires multiple queries. That means more hardware and more licenses to handle the same workload.
The real question is whether the use case needs the extra features and sacrifice associated with the graph tables. Will your algorithm need to make use of a larger collection of loosely connected objects? Is there some idea of locality or proximity that must be part of the algorithm? Is the rule about closeness or proximity strong enough that the algorithms will be able to ignore nodes that aren’t particular close? For instance, a restaurant recommendation algorithm might only suggest places that are nearby. Will users be happy with the recommendations if they don’t include a particularly notable place that’s a perfect fit but happens to lie just outside the search radius?
This article is part of a series on enterprise database technology trends.
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact.
Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
- up-to-date information on the subjects of interest to you
- our newsletters
- gated thought-leader content and discounted access to our prized events, such as Transform
- networking features, and more

