
DeepMind’s AlphaStar Final beats 99.8% of human StarCraft 2 players
Alphabet subsidiary DeepMind — which famously developed AlphaZero, a machine learning system that bested world champions in chess, shogi, and Go — returned to the video game domain once again in January with AlphaStar, which tackled Activision Blizzard’s popular real-time strategy title StarCraft 2. It beat top player Grzegorz “MaNa” Komincz and teammate Dario “TLO” Wünsch in a series of 10 matches, but a paper today published in the journal Nature describes a more impressive feat: Further training boosted AlphaStar’s ranking above 99.8% of all active players and earned it the level of GrandMaster — a spot among the top 200 regional players — for all three StarCraft 2 player races (Protoss, Terran, and Zerg).
DeepMind says this latest iteration of AlphaStar — AlphaStar Final — can play a full StarCraft 2 match under “professionally approved” conditions, importantly with limits on the frequency of its actions and by viewing the world through a game camera. It plays on the official StarCraft 2 Battle.net server using the same maps and conditions as human players, and it’s able to continuously self-improve without human intervention, courtesy a combination of general-purpose machine learning techniques including self-play via reinforcement learning, multi-agent learning, and imitation learning.
“StarCraft has been a grand challenge for AI researchers for over 15 years, so it’s hugely exciting to see this work recognized in Nature,” said DeepMind cofounder and CEO Demis Hassabis. “These impressive results mark an important step forward in our mission to create intelligent systems that will accelerate scientific discovery.”
Setting the stage
DeepMind’s forays into competitive StarCraft play can be traced back to 2017, when the company worked with Blizzard to release an open source tool set containing anonymized match replays. Subsequently, DeepMind launched the AlphaStar League, an AI model training environment that pits versions of AlphaStar against each other in a battle for supremacy.
StarCraft 2 is a real-time strategy game, a simulation where players gather resources (e.g., bases, structures, units, and technologies) to outgun or defend against opponents. It’s a blockbuster genre, and StarCraft 2 is the cream of the crop — since its release in 2010, it’s been played by millions of people and thousands of esports professionals globally.

Above: A figure showing how each technique used in AlphaStar affected its performance.
StarCraft 2 players have the aforementioned three races from which to choose. Controllable worker units gather resources to build structures and create new technologies, which in turn unlock more sophisticated units and structures. Much of the gameplay map is initially concealed from players so that they’re forced to seek out their opponents’ moves, and throughout, players must balance short-term tasks like constructing buildings and controlling units with planning winning moves and managing resources.
The DeepMind team notes that StarCraft 2 provides a rich test bed for AI research, particularly because it lacks a single best strategy. Adding to the challenge is the fact that metrics like opposing unit strength are hidden from players, a feature known as imperfect information. StarCraft 2 also emphasizes long-term planning, such that early game actions won’t necessarily pay off for a while. And it requires that players perform actions (and permutations of actions) with hundreds of different units and buildings continually.

Above: A top-down view of AlphaStar’s units, resources, and buildings in a match.
Suffice it to say the system devised to master it is a bit more complex than the company’s seminal Deep Q-network, which learned to play 50 different Atari 2600 games directly from their pixels. “AlphaStar advances our understanding of AI in several key ways,” explained AlphaStar project lead Oriol Vinyals. “[Through] multi-agent training in a competitive league can lead to great performance in highly complex environments, and imitation learning alone can achieve better results than we’d previously supposed.”
Self-play
AlphaStar primarily “learns” the subtleties (and indeed the basic rules) of StarCraft 2 through the above-mentioned self-play, in which it plays against itself to continue improving. Normally, AI agents engaged in self-play run the risk of catastrophic forgetting, in which they forget how to win against previous versions of themselves upon learning new information. This often kicks off a cycle in which the agents perceive valid strategies as less and less effective compared with a dominant strategy.
One solution is fictitious self-play, or playing against a mixture of all previous strategies. But this wasn’t robust enough to train AlphaStar. DeepMind instead pursued a novel, general-purpose training approach that became the AlphaStar League. Rather than prime all agents to win, one set of agents — main agents — attempt victory among a group of agents while another set of agents — exploiter agents — expose the flaws of the main agents. Thanks to this and to imitation learning techniques and latent variables that represent a wide diversity of opening moves, AlphaStar is prevented from forgetting throughout training.

Above: A figure depicting the evolution of AlphaStar agents.
StarCraft isn’t child’s play. Roughly 10^26 (100,000,000,000,000,000,000,000,000) possible actions are available to a single AlphaStar agent at each time step, and agents must make thousands of actions before learning if they’ve won or lost.
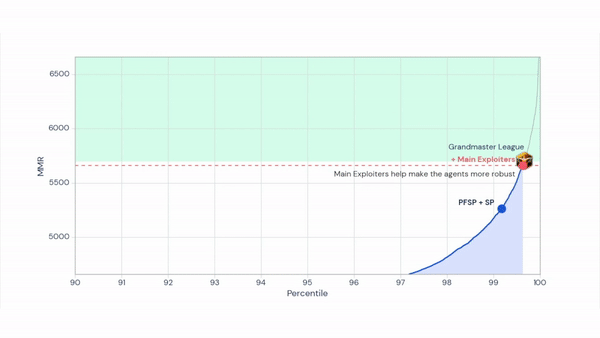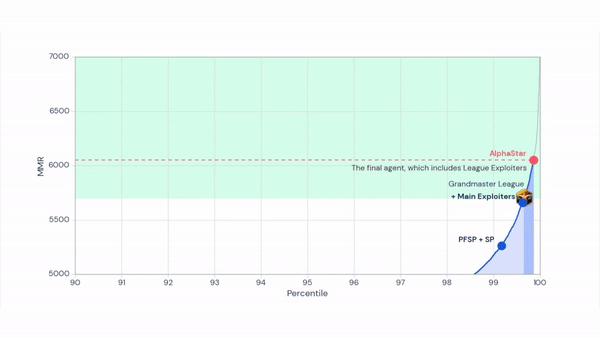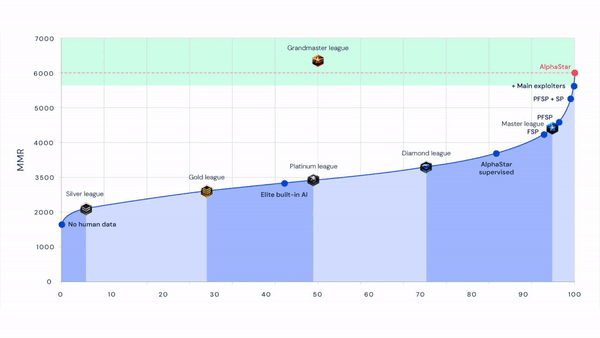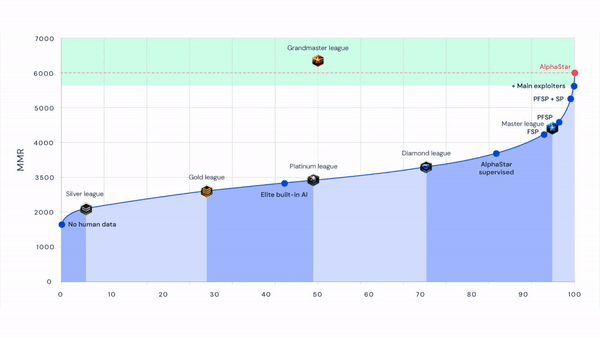
DeepMind imbued the agents with limited prior knowledge through imitation learning, during which AlphaStar agents received penalties whenever their actions differed from the supervised human demonstrations. Bolstered with techniques used for language modeling and a latent variable that encodes the distribution of opening moves from human games, the initial policy preserved and employed high-level strategies that beat 84% of active players. DeepMind reinforced those strategies by biasing exploration toward human strategies, and by tapping an algorithm for reinforcement leaning — an AI training technique that employs rewards to drive policies toward goals — that allowed the efficient updating of policies from older policies’ games.

Above: DeepMind’s AlphaStar competing against a human player.
“While AlphaStar’s strategies have at times differed from pro gamers’, in some respects it plays much like I do — like the delay it shows in noticing an action on the map,” said Wünsch, who participated in this latest study. “It was also exciting to see the agent develop its own strategies differently from the human players — like the way AlphaStar builds more workers than its base can support early in the game in preparation for later expansion. The caps on the actions it can take and the camera view restrictions now make for compelling games — even though, as a pro, I can still spot some of the system’s weaknesses.”
Early in the course of training, main agents were beaten by exploiter agents that discovered a “canon rush,” a strategy where a Protoss player builds early weapons outside of an enemy base beyond their sight radius. As training progressed, new main agents learned to defend against canon rush exploiters while defeating earlier main agents with superior economic play, unit composition, and control.

Above: DeepMind’s AlphaStar engaged in self-play.
Each agent was trained over 44 days using 32 third-generation tensor processing units (TPUS), application-specific integrated circuits (ASICs) developed by Google specifically for neural network machine learning. Almost 900 distinct players were created during League training, DeepMind reports.
Compared with StarCraft 2’s built-in AI at the Elite difficulty, which achieves an estimated matchmaking ranking (MMR) of roughly 3,300 on average, AlphaStar Final managed 6,275 MMR for Protoss, 6,048 MMR for Terran, and 5,835 MMR for Zerg. A less-capable AlphaStar model — AlphaStar Supervised — reached roughly 3,699 MMR, placing it above 84% of human players.
“AlphaStar achieved GrandMaster level solely with [an AI algorithm] and general-purpose learning algorithms — which was unimaginable 10 years ago when I was researching StarCraft AI using rules-based systems,” said Vinyals. “I’m excited to begin exploring ways we can apply these techniques to real-world challenges, such as helping improve the robustness of AI systems.”
Beyond games
DeepMind’s endgame isn’t merely superhuman StarCraft 2 players, of course. As with AlphaZero, the goal is to use learnings from AlphaStar to develop systems capable of solving society’s toughest challenges.
DeepMind is to this end currently involved in several health-related AI projects, including a trial at the U.S. Department of Veterans Affairs to develop a model capable of forecasting acute kidney failure (AKI) and identifying a majority of the most severe cases. More recently, DeepMind’s AlphaFold — an AI system that can predict complicated protein structures — placed first out of 98 competitors in the CASP13 protein-folding competition.
Beyond AKI and protein folding, DeepMind-led work is underway at Britain’s NHS to develop an algorithm that can search for early signs of blindness. The Alphabet subsidiary partnered with the Cancer Research UK Imperial Center at Imperial College London to refine AI breast cancer detection models, an effort that recently expanded to Jikei University Hospital in Tokyo. And in a paper presented at the Medical Image Computing and Computer Assisted Intervention conference in September, DeepMind researchers revealed they’d developed a system that could segment CT scans with “near-human performance.”
“The history of progress in artificial intelligence has been marked by milestone achievements in games. Ever since computers cracked Go, chess, and poker, StarCraft has emerged by consensus as the next grand challenge,” said DeepMind principal research scientist David Silver. “We addressed this challenge using general-purpose learning methods, rather than handcrafting a solution, and played under the same conditions that humans themselves face.”


